想要搜尋什麼內容?請嘗試以下連結:



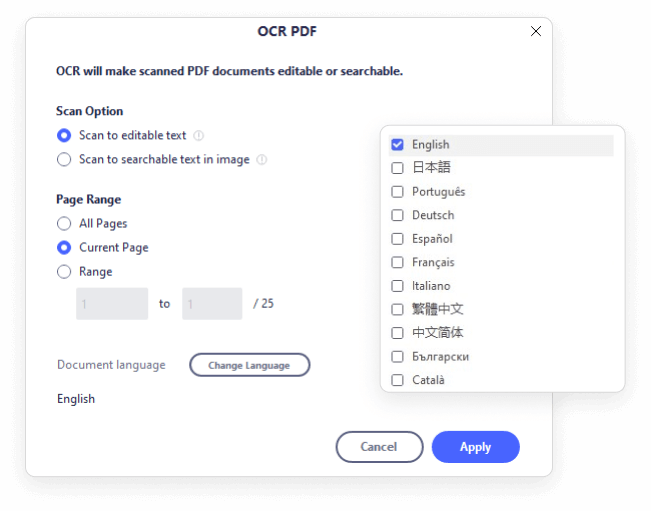
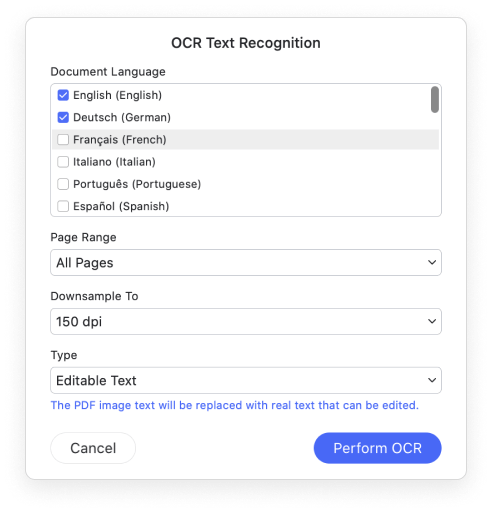
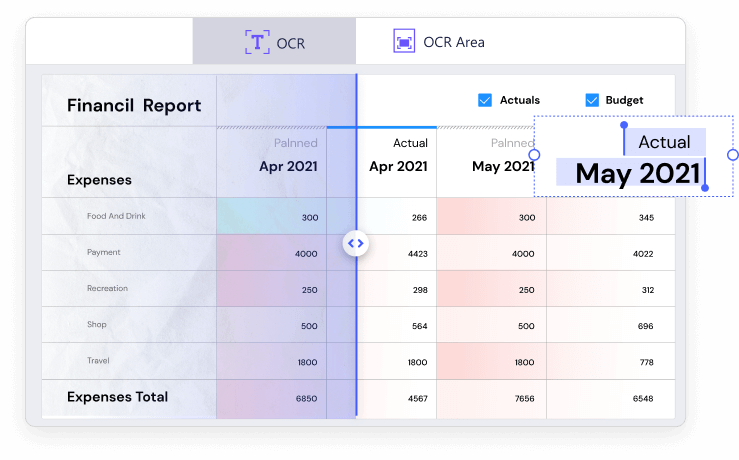
OCR stands for Optical Character Recognition. It is a widespread technology to recognize text inside images, such as scanned documents and photos.
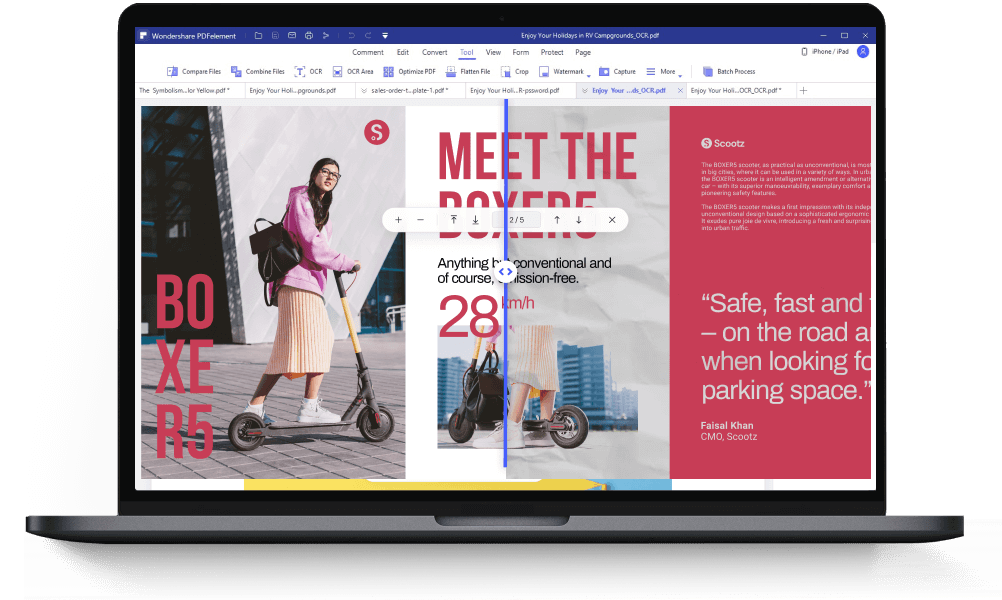
After performing OCR, PDFelement enables you to edit scanned PDF and image-based PDF as easily as a word document. When you add new text, it can match the look of the original fonts in your scanned PDF and image.
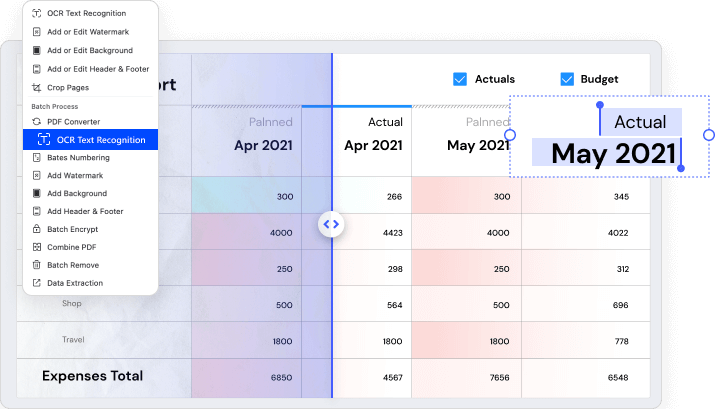
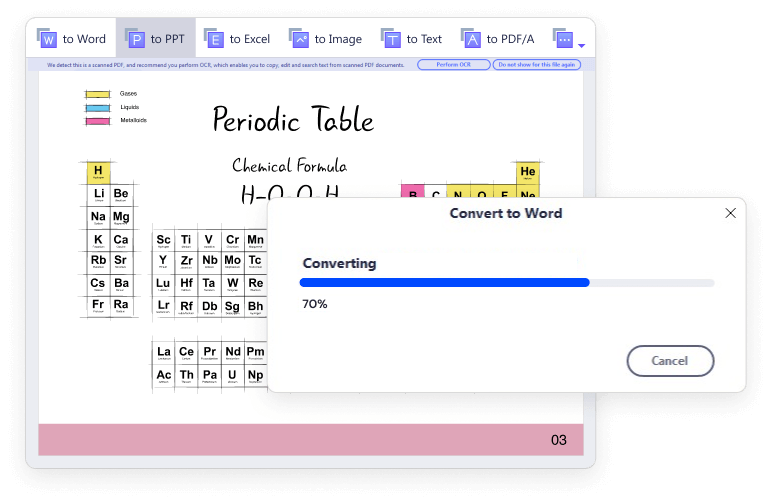
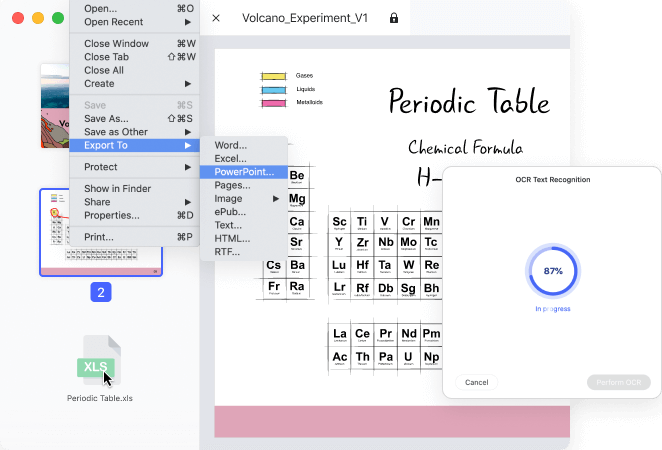
With OCR in Wondershare PDFelement, you can simply convert scanned PDF and image-based PDF to various formats with editable, selectable and searchable content, such as Microsoft Office formats, PPT, Pages, or a plain text document (TXT file).
Let manual data input become a thing of the past. PDFelement enables you to extract data from scanned PDF and image-based PDF with selected areas or from just extract data from form fields in PDF after performed OCR.
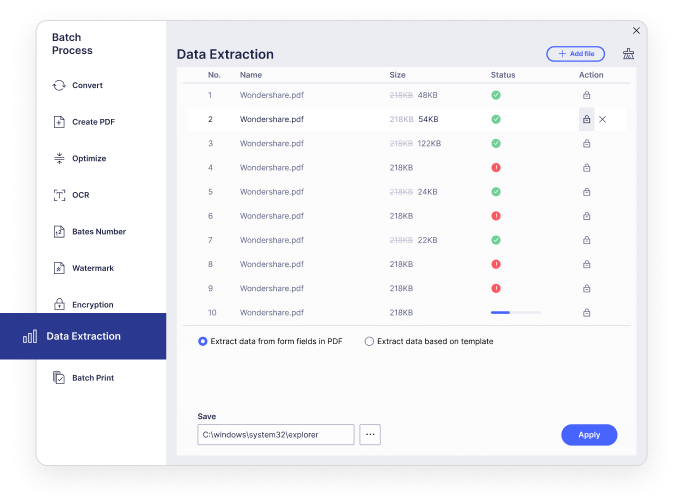
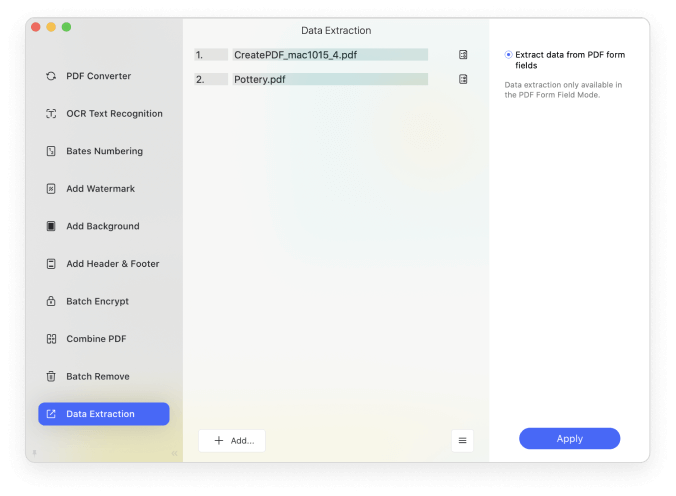
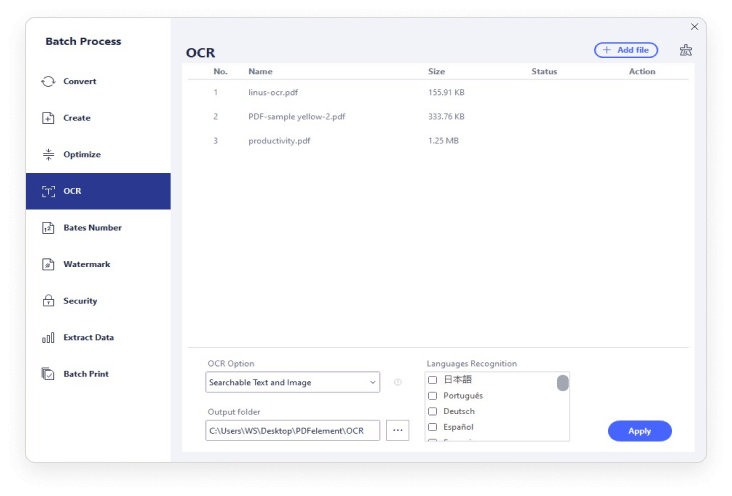
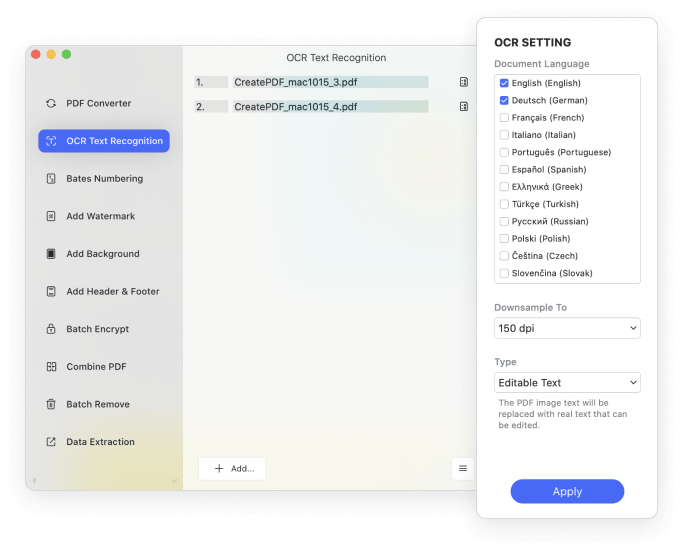
What do you do when you have stacks of scanned documents and image-only PDFs file that you need to search for a big case? PDFelement's Batch OCR feature helps to change multiple scanned PDF or image-based PDF files into editable and searchable PDF files.
The PDFelement's OCR supports dozens of languages, such as English, Portuguese, Japanese, Spanish, German, Italian, French, Bulgarian, Chinese Simplified, Chinese Traditional, Croatian, Catalan, and more languages.